·“得益于英伟达与台积电的紧密合作,专为GPU制造优化的4nm工艺让Ada Lovelace架构能够集成760亿个晶体管和超过18000个CUDA核心,较上一代Ampere架构多70%,能耗比相较Ampere则提升一倍。”
·“RTX光线追踪和神经网络渲染的时代正在全面展开,全新英伟达Ada Lovelace架构将其推向了新的高度。Ada的性能是上一代产品的4倍,正在为完全基于仿真的未来游戏铺路。”

经过几个月的猜测,英伟达创始人兼首席执行官黄仁勋终于在昨晚的GTC(GPU技术大会)2022上揭晓了RTX 40系列GPU的配置。

RTX 4090 图片来源:GTC大会
RTX 4090售价1599 美元,建议零售价为12999元人民币起,相比上一代RTX 3090的11999元上涨1000元,将于10月12日发布。RTX 40系列较上一代性能提升最高可达4倍,其特色光线追踪技术也是此次最重要的升级之一。
“RTX光线追踪和神经网络渲染的时代正在全面展开,全新英伟达Ada Lovelace架构将其推向了新的高度。”黄仁勋在GTC大会主题演讲上说。

RTX 4080 图片来源:GTC大会
RTX 4080则将于11月上市,目前提供的两个价格是16GB 版本为1199美元(人民币定价上探至9499元),12GB版本预计为899美元(人民币定价为7199元),相较上一代同定位的RTX3070Ti的4499元售价可谓“再创新高”。

RTX 40系列显卡售价 图片来源:GTC大会
在2021年“缺芯潮”等因素推动的业绩攀升后,英伟达2022年的情况却出现逆转。在美国芯片出口管制重拳和以太坊“合并”等事件影响下,该公司的发展前景被蒙上阴影。此前公布的第二季度财报已显示,该公司游戏部门的收入同比下降33%,环比降幅达44%。因此,此次GTC大会成为多方瞩目的焦点。
“加量也加价”:40系显卡性能、价格再创新高
RTX 4090采用了全新的第三代RTX架构,并使用台积电4纳米工艺制造。按照传统,新一代RTX也以计算机史上的名人命名,这次的是世界上第一位计算机程序员Ada Lovelace女士。
“得益于英伟达与台积电的紧密合作,专为GPU制造优化的4nm工艺让Ada Lovelace架构能够集成760亿个晶体管和超过18000个CUDA核心,较上一代Ampere架构多70%,能耗比相较Ampere则提升一倍。”黄仁勋在演讲中表示。
采用了Ada架构的40系显卡在性能表现上远远超过前辈30系显卡。这款RTX GPU主要用于游戏玩家和少数剩余的加密矿工,有望将游戏世界从一系列预先计算的图像转变为完全模拟的虚拟世界。
“Ada正在为完全基于仿真的未来游戏铺路。Ada的性能是上一代产品的4倍,为整个行业设立了新标准。”黄仁勋表示。
能效方面,RTX 4090功率为450W,与RTX 3090Ti保持一致,但英伟达称在同样功率下,4090的游戏表现较RTX 3090Ti提升一倍。
定位低一档的RTX 4080则有16GB与12GB两个显存版本,16GB版本集成了9728个DUDA核心。英伟达称RTX 4080 16GB的游戏性能两倍于RTX 3080,并超过了上一代旗舰RTX 3090Ti。而12GB版本的RTX 4080则集成了7680个CUDA核心,理论性能也超越了上一代旗舰RTX 3090Ti。
光线追踪技术与“元宇宙构建工具”
在新的Ada Lovelace架构中,SM 流处理器新增着色器重排序技术(Shader Execution Recording),黄仁勋强调其对GPU来说是革命性的,可实现对任务的实时重新调度,原理上与CPU的乱序执行技术类似。这项技术能够让英伟达显卡光线追踪性能提升2-3倍,在RTX 4090上输出90 TFLOPS,性能较上代提升两倍,整体游戏性能提升25%。
对于这项技术的原理,黄仁勋解释道,光线追踪的工作负载需要不同的线程处理,不同着色器之间很难合并工作,SER技术则能够即时安排着色器负载,从而提高执行效率,更好地利用GPU资源,打造更好的光线追踪效果。
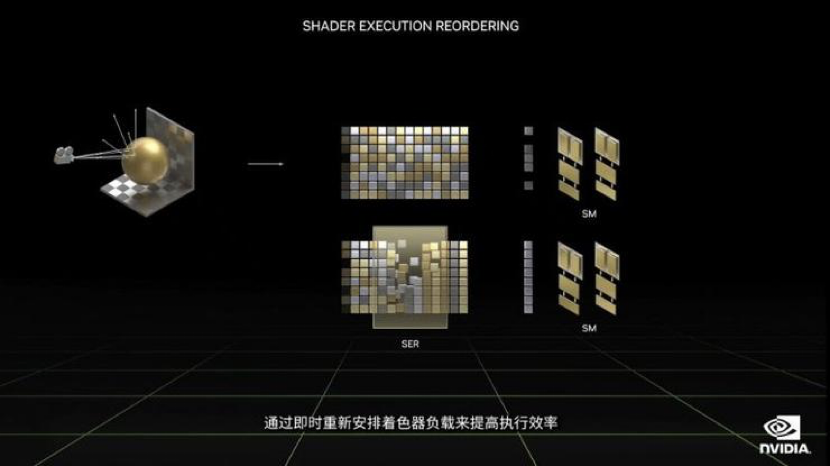
SER技术工作原理 图片来源:GTC大会
除此之外,黄仁勋还宣布了用于游戏和创作应用的第三代NVIDIA DLSS(Deep Learning Super Sampling,深度学习超级采样),表示这是神经网络图形技术的下一次革命。这项由人工智能驱动的技术可以生成全新帧,从而大幅提高游戏性能,也就是说,利用AI算法降低模拟真实物理环境所需要的计算量。
这也是第三代DLSS技术与之前最大的不同——生成的不再是像素,而是全面的画面帧。DLSS 3技术可以分析两帧连续的游戏图像,并向神经网络输入像素级的从帧到帧的运动方向和速度信息,此后神经网络模型将据此计算出中间帧。于是,中间帧由神经网络计算生成,不再涉及图形渲染,完全独立于游戏,这就能大大减轻游戏中即时演算的运算量。
“DLSS 3能够为Ada GPU带来远高于CPU可计算的帧率,从而让一些对CPU要求较高的游戏也从中受益。”黄仁勋说。据介绍,第三代DLSS技术相较于单纯渲染的方式可以将游戏性能提高4倍。

在现场,黄仁勋展示了对CPU要求比较高的《微软模拟飞行》游戏在开启DLSS 3前后的帧率变化。 图片来源:GTC大会
在RTX 40系列GPU和DLSS 3的配合下,3D设计师直接就可以利用精确的物理学和逼真的材料渲染完整的光线追踪环境,并实时查看效果。
自元宇宙一词热门以来,被称为“元宇宙构建工具”的Omniverse越来越受关注。黄仁勋发布了关于Omniverse的一系列重大更新。
Omniverse是英伟达在2019年推出的实时3D设计协作工具,黄仁勋曾在2021 GTC大会上介绍,“Omniverse可以让个人模拟制造出遵从物理规律的共享3D虚拟世界”。
现在,用户可以在Omniverse中创建数字孪生数据库——首个用于数据生成和数字孪生模拟的SimReady素材库。
除此之外,在昨天的GTC大会上,黄仁勋表示,Omniverse支持Ada Lovelace GPU。由此,Omniverse不仅能够加速各种复杂的3D工作流,还能够将光线追踪、AI和计算等复杂技术集成到3D流水线中,在VR中也能实现实时光线追踪——Cloud XR。
在NVIDIA Omniverse Cloud的支持下,Omniverse可以为3D工作流提供无缝协作体验。黄仁勋表示,“NVIDIA Omniverse Cloud是一款IaaS产品,可以连接在云上、本地和单个设备上,运行Omniverse应用。”

NVIDIA RTX Remix 图片来源:GTC大会
在现场黄仁勋还展示了NVIDIA RTX Remix。NVIDIA RTX Remix可以让爱好者为各种经典游戏制作mod添加RTX光追效果。即捕捉下经典游戏画面,然后利用AI工具自动增强材质,并通过光线追踪和DLSS快速将游戏RTX化。看起来此举是为了让更多人开始使用和熟悉Omniverse。
单颗2000TOPS的“核弹”级产品:Atlan取消,雷神接棒
在2021年春季的英伟达GTC大会上,黄仁勋宣布了用于自动驾驶汽车的Atlan芯片,计划于2025年用于量产车应用。但在昨晚的2022年秋季GTC上,黄仁勋宣布Atlan已被取消,取而代之的是一种名为Thor(雷神)的新设计,该设计将提供两倍的性能和数据吞吐量,但仍将在 2025年推出。
黄仁勋没有将Thor描述为自动驾驶芯片,而是表示,这颗SoC是为汽车的中央计算架构而生,用这一颗芯片打造一个控制器,即可同时为自动泊车、智能驾驶、车机、仪表盘、驾驶员监测等多个系统提供算力。
Thor SoC预计将通过770亿个晶体管提供2000 TOPS的整数计算能力以及2000 TFLOPS的浮点性能。相比之下,2016年为特斯拉AutoPilot的第2版(与Pascal GPU 组合)提供动力的Parker SoC提供了大约1个TOPS,2020年紧随其后的是提供30个TOPS的Xavier芯片。
单颗2000 TOPS可以说是“核弹”级的产品,目之所及没有对手。
黄仁勋介绍,这样的性能来源于对CPU(Grace)、GPU(Ada Lovelace)和处理 Transformer模型的引擎(Hopper)进行了升级。“Hopper提供了令人惊叹的 Transformer引擎和Vision Transformer的快速变革,而Ada是英伟达最新的GPU产品,基于4nm工艺打造。”
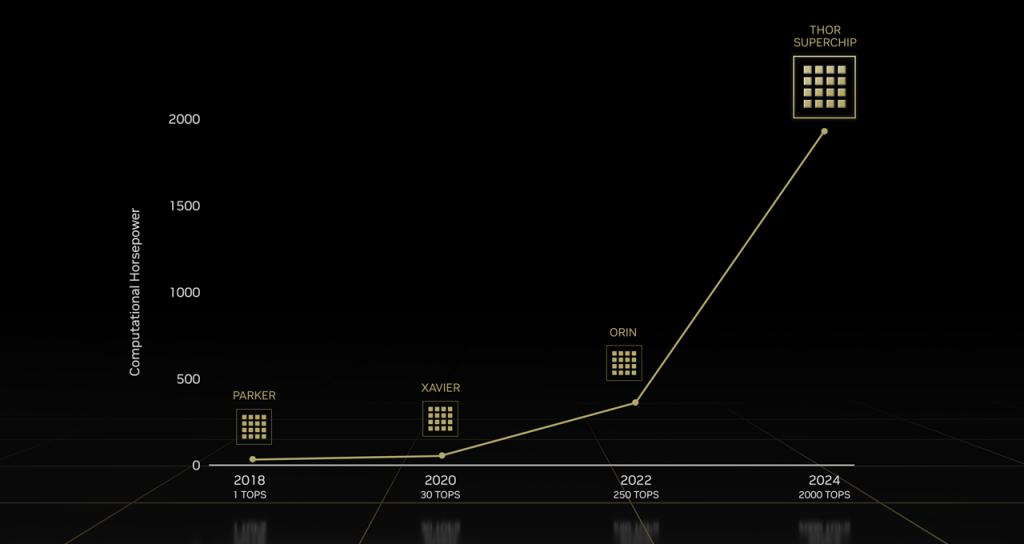
英伟达自动驾驶芯片演进
Thor可以被配置成多种模式,可以将2000 TOPS和2000 TFLOPS全部用于自动驾驶工作流;其2000 TOPS的算力也可以分开用,如一部分用于驾驶舱AI和信息娱乐系统,另一部分用于辅助驾驶。Thor中的多计算域隔离允许并发、对时间敏感的多进程无中断运行,可以在一台计算机上同时运行Linux、QNX和Android。
将自动泊车、智能驾驶、车机、仪表盘、驾驶员监测等多个系统的计算统一到Thor上完成,意味着对汽车EE架构的显著简化,同时可以降低产品的布线规模,降低车重,从而达到降低成本的作用。
除此之外,英伟达还发布了一款微型机器人系统级模块芯片Jetson Orin Nano,它的速度较之前的Jetson Nano快了80倍。Jetson Orin Nano可以运行NVIDIA Isaac机器人堆栈,并具有 ROS 2 GPU 加速框架。









